

Small sample classification of natural earthquakes and blasting based on GA-XGBoost
-
摘要:
由于爆破数据数量有限,利用分类法识别天然地震与爆破会遇到诸多困难。鉴于此,本文建立了高维特征小样本数据集,基于XGBoost模型利用遗传算法(GA)实现对主要影响XGBoost模型分类准确率的迭代次数、最大树深和学习率等三个重要超参数的自主寻优,构建出了GA-XGBoost模型,并将该模型应用于功率谱特征样本集,结果显示:爆破与天然地震的分类准确率高达94.094%;相比于传统的GS-XGBoost模型(准确率91.787%),GA-XGBoost模型在显著提升分类准确率的同时,其运行时间也由409.26 s缩短至55.48 s,效率提高了超86%。由此可见,本文建立的GA-XGBoost模型兼顾准确率、稳定性与效率,在小样本分类任务中具有良好的应用前景。
Abstract:The rapid development of seismic networks and the advancement of monitoring equipment have enabled the recording of various seismic events, including natural earthquakes and man-made blasting activities. Notably, nuclear explosions can also be detected through seismic monitoring, and this detection is a crucial aspect in the verification process of the Comprehensive Nuclear Test Ban Treaty. However, distinguishing between natural seismic events and those caused by blasting is challenging. Both appear as fluctuating curves on seismic records and share a striking resemblance, making manual identification resource-intensive and prone to human error, potentially leading to misjudgments and confusion in earthquake catalogs. This issue can compromise the effectiveness of earthquake early warning systems and emergency response measures. Therefore, the automated classification and discrimination between seismic events originated from natural sources and those caused by blasting are of great significance for both earth science research and national defense.
Currently automatic classification techniques predominantly rely on deep learning, which typically requires extensive labeled datasets for training. Obtaining sufficient high-quality data for nuclear explosion events can be challenging due to their unique nature, limiting the application of deep learning for this purpose. This paper focuses on the classification and discrimination of natural earthquakes and blasting with limited sample data. The test data consists of vertical component recordings of short-period natural earthquakes and nuclear explosions. These recordings are preprocessed by employing the SPA method to eliminate the trend component. Subsequently, complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) is utilized to extract a series of intrinsic mode functions. Wavelet thresholding is applied to reduce noise, and then the denoised components are reconstructed to generate the final signals. The preprocessed signals are expanded by translation and noise injection techniques. This process results in a final training set, which consists of 500 event signals for each category.
The features from the energy spectrum, power spectrum, and cepstrum are extracted to form a high-dimensional small-sample dataset. Given the excellent performance of the eXtreme Gradient Boosting (XGBoost) model in small-sample classification tasks, this study employs its strategy of aggregating weak classifiers. The model improves the accuracy by performing second-order Taylor expansion on the objective function, thereby retaining more target-related information. The XGBoost model is then utilized to classify natural and blasting seismic events. To address the complexity and numerous parameters in the conventional XGBoost, this paper employs the genetic algorithm (GA) to optimize three key hyperparameters that significantly impact classification accuracy: the number of iterations, maximum tree depth, and learning rate. The GA’s advantages include its independence from initial conditions, robustness, and suitability for complex optimization problems. Taking advantage of these strengths, the GA-XGBoost model is constructed.
In the tests conducted with the high-dimensional small-sample dataset, the GA-XGBoost model achieved the highest classification accuracy of 94.094% on the power spectrum feature set. When using the power spectrum feature as input, the GA-XGBoost model outperformed both LSTM and GS (grid search)-XGBoost models in accuracy. Notably, compared with the GS-XGBoost, the GA-XGBoost model improved the classification accuracy by 2.037% and reduced the runtime from 409.26 seconds to 55.48 seconds, increasing operational efficiency by over 86%. However, the preprocessing and feature extraction process presented in this paper is relatively complex and requires professional expertise. Moreover, the paper utilizes a 1500-dimensional power spectrum feature. It should be noted that different feature dimensions can impact test results. Hence, it is necessary to select the appropriate feature dimension according to the specific data and tests.
Although the tests have verified the classification effectiveness of high-dimensional features such as the power spectrum, energy spectrum, and cepstrum, the optimal features may vary with different datasets. Therefore, it is essential to conduct tests and select the most suitable features based on the available data. Finally, while the study explores hyperparameter optimization using genetic algorithm, with the emergence of new optimization algorithms, there is potential for further investigation into these algorithms for hyperparameter selection. Overall, the tests demonstrate that the GA-XGBoost model offers a balance of accuracy, stability, and efficiency, showing promise for small-sample classification tasks.
-
Keywords:
- seismic events /
- XGBoost /
- genetic algorithm /
- small sample /
- feature extraction
-
引言
随着地震台网的加速建设和地震监测仪器的更新改进,除天然地震以外,越来越多的人工爆破事件也得以清晰记录。天然地震多发生在地壳深部,震源为非对称剪切源;而人工爆破多发生在浅层地表附近,为对称膨胀源(黄汉明等,2010)。二者虽然震源性质不同,但在台站记录上均显示为具有较高相似性的波动曲线。一直以来,工作人员主要依靠手动识别天然地震与爆破事件(黄汉明等,2010;董祎玮等,2017;田宵等,2022)。手动识别事件需要持续地观测和分析,其效率低而且还可能因为工作人员的经验不同而造成事件性质误判,将爆破事件混入天然地震目录,从而增加地震的误触发率,影响地震预警、地震速报以及地震应急的时效和准确性(和雪松等,2006;Astiz et al,2014)。因此如何准确地、自动地区分天然地震与人工爆破事件始终是相关研究中的热点问题(Stump et al,2002;Rabin et al,2016;隗永刚等,2019)。国内外学者也就此开展了大量研究,例如:陈润航等(2018)使用卷积神经网络(convolutional neural network,缩写为CNN)进行天然地震与爆破事件的分类,准确率约为97.1%;Linville等(2019)分别使用CNN和循环神经网络(recurrent neural network,缩写为RNN)识别美国犹他州(Utah)采石场事件,准确率高达98%。以上方法均是运用大量样本数据对分类模型进行训练,但核爆的样本数据稀缺,而且由于保密、安全或伦理问题,在一些特殊领域,更难以获得大量数据。此外,大量样本还需要人工进行数据标注,消耗不少的人力和物力。因此,无论是为了缓解传统深度学习算法对大数据的严重依赖,还是减少人工打标签造成的低效人力消耗,天然地震与爆破事件的小样本分类研究都十分必要(Kiszely,2001;Kekovalı et al,2012;Koper et al,2016;Yavuz et al,2019)。
XGBoost (Extreme Gradient Boosting)是对GBDT (gradient boosting decision trees)算法的改进,在小样本分类问题中能够达到超预期的效果。其思想是将简单的弱分类器集成起来使用,同时对目标函数进行二阶泰勒展开,留存更多目标信息,以此提升模型的准确性。但常规的XGBoost模型具有参数过多、计算复杂等特点,因此优化模型参数尤为重要。遗传算法(genetic algorithm,缩写为GA)作为一种随机型全局搜索优化方法,模拟了自然选择和遗传过程中发生的复制、交叉(crossover)和变异(mutation)等现象。相较于其它算法,遗传算法具有优化结果与初始条件无关、鲁棒性较强以及适用于复杂的优化问题求解等优势。因此考虑将GA算法与XGBoost算法结合使用,融合二者的优点,有望在小样本地震分类上取得较好的效果。杨帅等(2022)提出了融合遗传算法和XGBoost的转录组分析方法— GA-XGBoost,该方法有效提升了对转录组数据的分析能力和效率;柏晗等(2022)构建了一种基于遗传算法特征选择的XGBoost土壤铜元素反演模型GA-XGBoost,并通过试验证明所构建模型具有较好的性能;赵昕迪(2022)构建基于探索性因子分析的GA-XGBoost组合预测模型来评估绝缘子表面的污秽状态,验证了所构建模型具有更短的预测时间、更高的预测精度和更强的泛化能力。然而在地震事件分类任务中,对XGBoost模型的研究还较少,对XGBoost的改进也停留在利用网格搜算法(李欣,俞卫琴,2020)、贝叶斯优化等传统方法上,因此利用遗传算法进行XGBoost模型的优化改进尚需进一步深入。
鉴于此,本文拟基于短周期天然地震与爆破事件的小样本数据,构建GA-XGBoost模型进行小样本事件的分类研究,以期通过试验分析实现该模型对影响模型分类精度的关键超参数的自主寻优,有效解决XGBoost模型参数选择依赖人工经验的缺点,显著提升算法寻优能力,同时提高模型的分类准确率和稳定性。本研究旨在为小样本条件下天然地震与爆破事件的分类问题提供一种高效、可靠的算法框架,为地球科学研究、国防安全建设及国家防震减灾工作提供地球物理过程理解、军事威胁监测、地震预警与灾害响应参考。
1. 数据与方法
1.1 高维特征样本集构建
1.1.1 完全集合经验模态分解联合小波阈值降噪
待识别数据类型包括短周期天然地震事件和短周期爆破事件,对地震事件进行分类识别前需要对记录进行筛选并拾取P波到时。目前应用较广泛的初至波拾取方法有频谱比法、长短时窗比值(short term averaging/long term averaging,缩写为STA/LTA)算法、赤池信息准则(Akaike information criterion,缩写为 AIC)和分形分维法(孟娟等,2022)等,因STA/LTA算法(Stevenson,1976)更为快速简单,本文选用此方法进行波形记录筛选,具体流程如下:
1) 截取包含P波和S波在内的全波段波形记录;
2) 设定STA与LTA的窗长分别为0.2 s和1 s,阈值为2;
3) 基于STA/LTA进行 P波拾取,取初至前5.6 s至初至后20 s的记录波形,采样频率为40 Hz,每条记录为1 024个点。
按以上步骤进行波形筛选,得到60条爆破记录和若干条天然地震记录。由于短周期爆破数据相较于短周期天然地震数据少得多,为了避免因样本分布不均使数据集划分不合理而产生模型训练偏差、评估指标失真以及少数样本信息丢失等问题,从天然地震数据中随机挑选60条,在小规模数据集上用交叉验证方法评估模型。原观测波形中含有大量噪声会严重影响拾取结果,因此在进行拾取前需要进行降噪处理。
具体降噪流程如下:首先利用平滑先验分析方法(smoothing prior analysis,缩写为SPA)对原始数据进行去趋势项;其次,对去趋势项的信号进行完全集合经验模态分解(complete ensemble empirical mode decomposition with adaptive noise,缩写为CEEMDAN)得到固有模态函数(intrinsic mode function,缩写为IMF)并去残差项;最后,分别计算各IMF与原信号的余弦相似度,分别设定保留阈值a与丢弃阈值b,当余弦相似度大于a时,则保留此IMF,当余弦相似度小于b时,则丢弃此IMF,而对于介于b与a之间的IMF,则利用小波分解进行阈值降噪处理,将降噪后的信号与保留的模态进行重构即可得到降噪后的信号。保留阈值a是通过计算占总能量30%以上的模态的余弦相似度并对其进行统计平均得到,丢弃阙值b则通过计算噪声记录与原始信号的余弦相似度并对其进行统计平均得到,此处a=0.5,b=0.15。
上述SPA方法最早应用于心电信号处理,其计算过程简单,计算量极小,仅选择单一参数即可快速分离原始数据趋势项和去趋势项;CEEMDAN是Torres等(2011)在经验模态分解(empirical mode decomposition,缩写为EMD)和集合经验模态分解(ensemble empirical mode decomposition,缩写为EEMD)的基础上提出的一种新的信号分解方法.该算法通过在分解的各个阶段添加自适应白噪声较好地解决了EMD存在模态混叠以及EEMD存在残余噪声的问题(Yeh et al,2010;Torres et al,2011;戴邵武等,2019);小波阈值去噪的实质是一个抑制信号中无用部分、增强有用部分的过程。去噪的主要过程为:① 分解,即选定一种小波对信号进行n层小波分解;② 阈值处理,即对分解的各层系数进行阈值处理,获得估计小波系数;③ 重构,即对去噪后的小波系数进行重构,获得去噪后的信号。
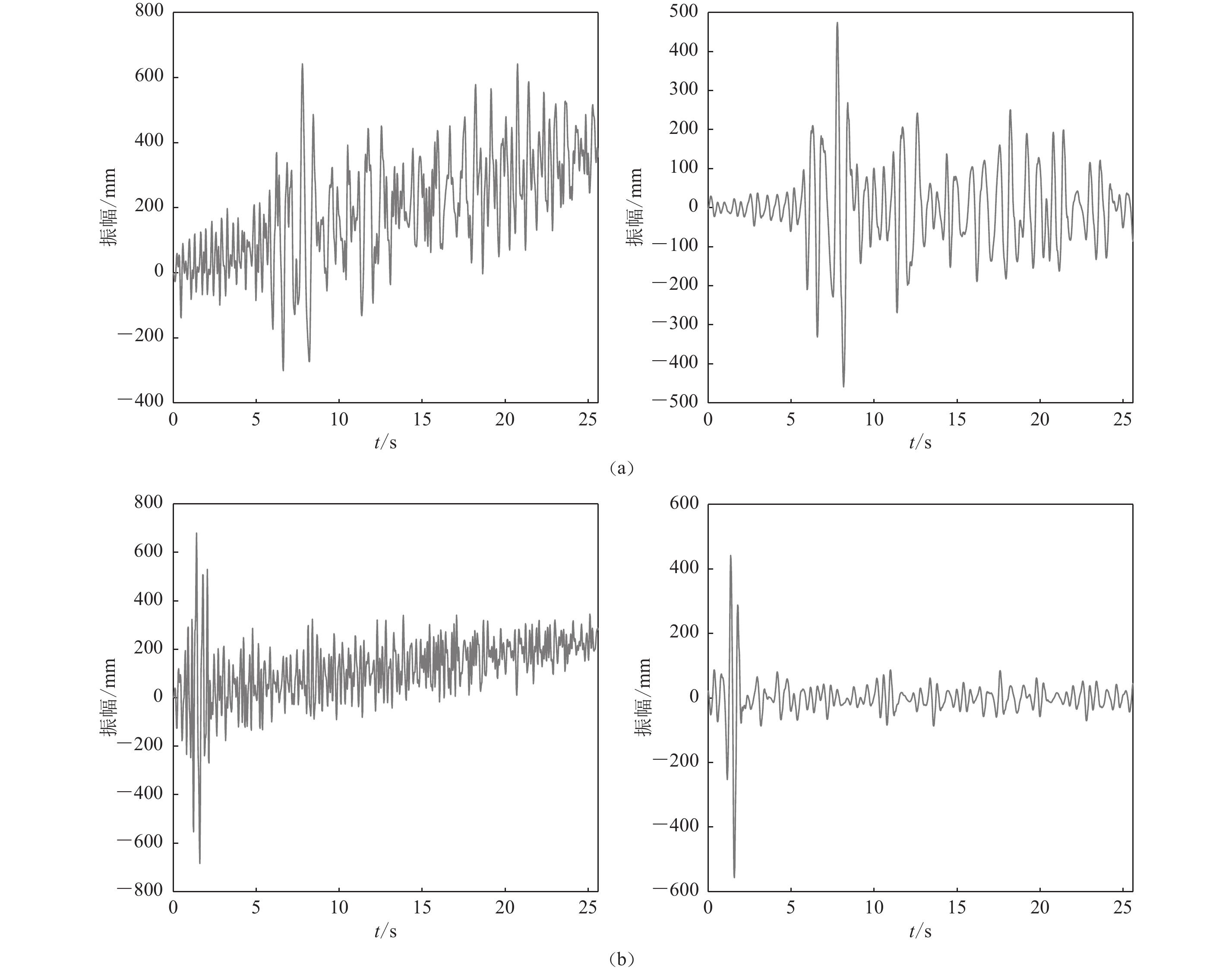
预处理前后天然地震与爆破的波形对比如图1所示,可以看到,经过降噪处理,信号的细节信息得以较好地保留,同时信号的基线偏离问题得到妥善解决,噪声也基本得到压制,这样更有利于下一步分析。
![]() 图 1 预处理前(左)、后(右)天然地震(a)和爆破(b)的波形对比图Figure 1. Comparison of waveforms of a natural earthquake (a) and a nuclear explosion (b)before preprocessing (left) with those after preprocessing (right)
图 1 预处理前(左)、后(右)天然地震(a)和爆破(b)的波形对比图Figure 1. Comparison of waveforms of a natural earthquake (a) and a nuclear explosion (b)before preprocessing (left) with those after preprocessing (right)1.1.2 高维特征样本集构建
对预处理后的数据分别提取能量谱、功率谱和倒谱三种高维特征,并将其作为模型输入进行分类识别,训练集与测试集分别按照5 ∶ 1和4 ∶ 2进行划分,并确保两个集合之间的样本互不重叠。为提高训练的准确性,对训练集进行数据扩充。原始数据为60条天然地震和60条核爆数据,分别从中各任意选择50条数据作为训练集,并对其进行扩充。首先是平移扩充:原数据有
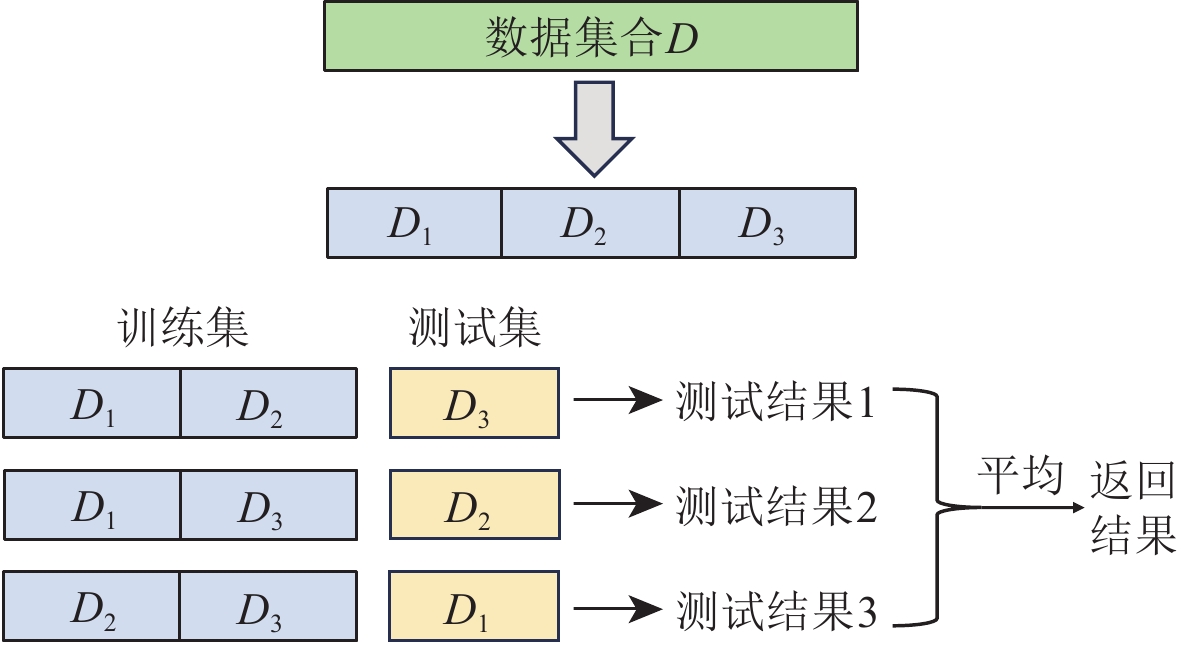
1024 个点,以5个点为步长进行平移,超出数据长度的部分进行补零操作,平移4次共计得到200条新数据;之后进行加噪扩充,即对平移扩充得到的200条数据和原始的50条数据添加5 dBW的高斯白噪声,进而得到250条新数据。通过数据扩充操作,最终得到500条天然地震数据和500条爆破数据。对得到的两类信号(各500条数据)分别提取1500 维的能量谱、功率谱以及倒谱特征作为最终的训练集样本(Li et al,2024)。采用6折交叉验证与3折交叉验证(图2)的方式,对模型的整体性能进行检验。
1.2 GA-XGBoost分类模型
1.2.1 XGBoost
假设一个学习器模型为f(x),则由n个学习器模型集成的XGBoost模型(Chen,Guestrin,2016)为:
$$ \hat{Y}=\sum\limits_{k=1}^nf_k ( x_i ) \text{,} $$ (1) 式中,xi为第i个样本的预测值,k为模型的数量,fk为第k个学习器模型。
XGBoost的损失函数为:
$$ L=\sum\limits_{i=1}^n {l ( {y_i}\text{,} {Y_i} ) } \text{,} $$ (2) 式中,yi为第$i$个样本的真实值,Yi为第i个样本的预测值,L为损失函数,l表示单个样本的损失值。
XGBoost的目标函数为:
$$ \mathrm{OBJ}=L+\sum\limits_{k=1}^n\mathit{\Omega} ( f_k ) \text{,} $$ (3) $$ \mathit{\Omega }( f) =\gamma T+\frac{1}{2}\lambda\sum\limits_{j=1}^T\omega_j^2\text{,} $$ (4) 式中,Ω(fk)为正则项,T为叶子节点数目,ω为权重,γ与λ为惩罚项,所以目标函数的正则项由生成的所有决策树的叶子节点数量和所有节点权重所组成向量的L2范式共同决定。从偏差、方差平衡角度来讲,正则项降低了模型的方差,使学习出来的模型更加简单。同时损失函数L还采用式(5)的二阶泰勒展开式,这样能够留存更多目标信息,有效地提高算法的收敛速度和准确性,
$$ \begin{split} L\text{≈}\sum\limits_{i=1}^nl\left[y_i\text{,} Y_i^{ \ t-1\ }+g_if_i ( x_i ) +\frac{1}{2}h_if_i^2 ( x_i ) \right]\text{,}\end{split} $$ (5) 式中gi和hi分别为损失函数的一阶导数和二阶导数。
1.2.2 长短时记忆网络
长短时记忆网络(long-short term memory network,缩写为LSTM)是一种特殊的循环神经网络,是为了解决一般RNN存在的长期依赖问题而专门设计的,通过增加门控单元模型能够精确地描述时间序列的长期依赖关系,还能够更有效地提取时序数据上的信息,同时有效地规避 RNN 所存在的梯度消失等问题(王义国等,2024)。通过试验得出,当长短时记忆网络隐藏层为
1500 层、同时加入dropout层并取dropout=0.6时,分类结果较好,下面长短时记忆网络的参数均按此设置。1.2.3 GS-XGBoost分类模型
网格搜索是一种穷举搜索方法,它通过遍历超参数的所有可能组合来寻找最优超参数。网格搜索首先为每个超参数设定一组候选值,然后生成这些候选值的笛卡尔积,形成超参数的组合网格;接着网格搜索会对每个超参数组合进行模型训练和评估,从而找到性能最佳的超参数组合。GS-XGBoost分类模型利用GS算法对XGBoost的迭代次数、最大树深和学习率进行优化,选出最佳的超参数组合并带入XGBoost模型进行分类。
1.2.4 GA-XGBoost分类模型
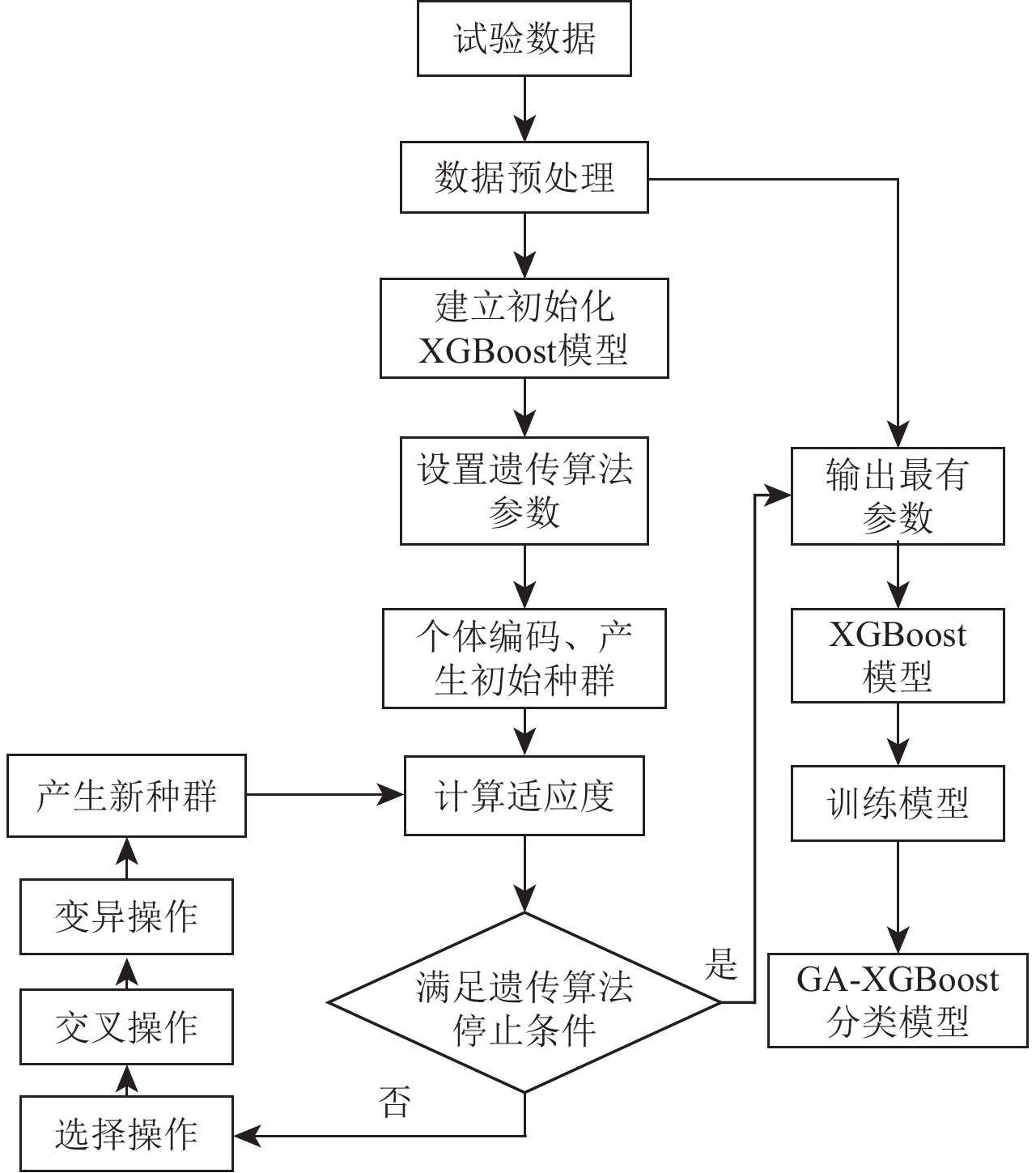
遗传算法通过数学的方式,利用计算机仿真运算将问题的求解过程转换成类似生物进化中染色体的基因交叉、变异等过程,类似于生物在自然界中的种群更替(陈法法等,2016)。遗传算法中种群的染色体逐代进行迭代,直至满足规定的终止条件,此时最终留存在种群中拥有最高适应度函数值的个体,即作为遗传算法求解数学优化问题的近似最优解。相较于一些常规的优化算法,遗传算法在求解较为复杂的组合优化问题时,通常能较快地获得较好结果。将遗传算法与XGBoost算法结合后能够留存更多目标信息,以提升模型准确性,使模型具有很强的泛化能力。GA-XGBoost模型针对XGBoost的三个重要超参数,即迭代次数、最大树深和学习率,进行优化,解决了遗传算法中个体适应性度量的设定问题和 XGBoost参数设置问题,并保留了两个算法各自的优点(Choi et al,2021;Ewees et al,2021;Gomes et al,2021;Luat et al,2021;Ouyang et al,2021;Roui et al,2021)。GA-XGBoost 算法的流程如图3所示。
GA-XGBoost算法的主要步骤如下:
1) 输入试验数据并划分训练集和测试集;
2) 按上文数据处理方法对试验数据进行预处理;
3) 建立初始化XGBoost模型;
4) 设置遗传算法参数的编码方式、初始种群、变异概率等;
5) 计算种群内的个体适应度值;
6) 对适应度值进行判断,若满足停止条件,即连续多代种群中个体的平均适应度不变,即可认为种群已经成熟,此时算法终止,将输出的最佳参数带入XGBoost模型进行训练,否则执行下一步;
7) 进行染色体的选择、交叉和变异操作产生新种群;
8) 再次对适应度值进行判断,若满足停止条件,则将输出的最佳参数带入XGBoos模型进行训练,否则继续执行上一步;
9) 利用训练好的GA-XGBoost模型进行分类。
在GA-XGBoost算法中,结合样本的数量,设置遗传算法参数,染色体的编码方式采用二进制编码,初始种群数目设为 20,最大迭代次数为 100,进化停滞判断阈值设为 1×10−6,进化停滞计数器的最大上限值设为 10,交叉概率设为 0.95,变异概率设为 0.05。待优化参数的初始范围分别设置为:最大树深为$ [ $1,50$ ] $,学习率为$ [ $0.01,0.3$ ] $,迭代次数为$ [ $1,100$ ] $。
为了提高模型的预测准确率和计算效率,将数据集归一化至$ [ $−1,1$ ] $,并将训练集的均方误差(mean square error,缩写为MSE)指定为适应度函数,利用优化算法全局寻优能力在设置的搜索空间内对 XGBoost 超参数不断迭代优化,以构建最优GA-XGBoost 分类模型。最终得到最优参数的平均值:迭代次数为28;最大树深为43;学习率为0.24。
2. 结果及试验分析
2.1 评价指标说明
本文将采用准确率A、召回率R和运行时间${t}$共三个不同的性能指标对本文的模型进行评估。各指标的定义如下:
$$ A=\frac{\mathrm{TP}+\mathrm{TN}}{\mathrm{TP}+\mathrm{TN}+\mathrm{FP}+\mathrm{FN}}\text{,} R=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}}\text{,} t=t_{\mathrm{e}}-t_{\mathrm{s}}\text{,} $$ (6) 式中:TP为真阳性,表示被正确识别为正例的个数;FP为假阳性,表示被错误识别为正例的个数;TN为真阴性,表示被正确识别为负例的个数;FN为假阴性,表示被错误识别为负例的个数;ts和te分别为模型运行的开始时间和结束时间;A是对分类器整体正确率的评价;R代表所有正例被正确分类的比例,能衡量分类器对正类的识别能力;t为训练模型所需要的时间。准确率、召回率是分类器的常用性能度量指标,一般认为具有高准确率、高召回率的分类器是一个优秀的分类器,如果运行时间更短,则说明分类器具有更高的时间效率。
2.2 试验及结果分析
分别将提取的
1500 维能量谱特征、功率谱特征及倒谱特征构建的高维小样本数据集作为各分类模型的输入,模型参数按照上文所述设置后进行分类试验。各模型谱特征结果如图4中的柱状条所示,根据多次试验得到:当提取
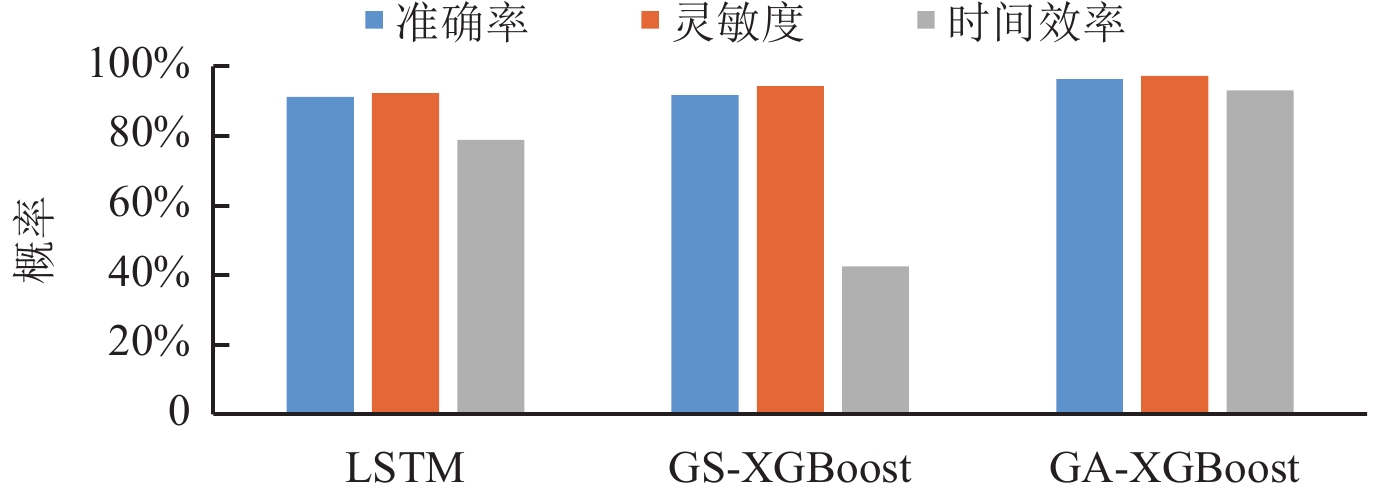
1500 维功率谱特征作为基础XGBoost模型输入时,分类准确率较高,因此将1500 维功率谱特征数据集分别作为XGBoost,LSTM,SSA-XGBoost模型和GA-XGBoost模型的输入进行分类,结果取3折交叉验证与6折交叉验证的平均值。各模型准确率结果如图4中的折线所示,可见XGBoost,LSTM,GS-XGBoost和GA-XGBoost模型的准确率分别为90.846%,90.051%,91.787%和94.094%,XGBoost相较于LSTM有着更高的分类精度,验证了XGBoost模型在小样本分类任务中的适用性。GS-XGBoost模型的准确率相较于基础XGBoost模型提高约1%,而GA-XGBoost模型则提高3%左右,表明GA-XGBoost模型的寻优效果更好,最优参数在此分类任务中更为有效。为了进一步验证模型的稳定性,我们进行50次独立重复试验,其中运行效率以XGBoost模型运行时间为基准进行计算,试验结果评估指标的平均值如图5所示,可见GA-XGBoost模型的分类准确率、召回率以及时间效率均明显优于另外两种方法,特别是GA-XGBoost模型相较于传统GS-XGBoost模型,准确率提高2.037%,时间效率提高超86%,说明GA-XGBoost模型在提升分类准确率与召回率的同时,也显著提升了运行效率,并且通过多次试验证明其具有较强的稳定性。在实际地震事件分类过程中,时间效率也是至关重要的一个参数,能够为应急救灾争取更多时间。因此,该模型能够兼顾准确率、稳定性和时间效率,具有乐观的应用前景。
![]() 图 5 三种模型试验结果评估指标对比图Figure 5. Comparison of evaluation indices of the test results for the three models
图 5 三种模型试验结果评估指标对比图Figure 5. Comparison of evaluation indices of the test results for the three models3. 讨论与结论
地震信号的分类识别对于地震目录建立的质量以及对地震学的相关研究具有重要作用。本文对天然地震与爆破的小样本数据分类问题进行了研究,对预处理后的波形数据提取了
1500 维功率谱特征,将XGBoost模型作为分类器,利用遗传算法优化建立了GA-XGBoost模型,该模型在提升寻优能力的同时可兼顾时间效率,进一步提高了模型的分类准确率和分类稳定性。基于以上分析,本文所得结论如下:1) 相较于LSTM模型,XGBoost模型在小样本的天然地震与爆破事件分类中的准确率更高,达到了90.846%,分类准确率高、稳定性强,表明XGBoost模型在小样本地震事件分类中具有良好的应用前景。
2) 多维功率谱特征对于天然地震与爆破信号具有良好的分类性能。
3) 利用GA-XGBoost模型进行分类,能够在保证高准确率与强稳定性的同时兼顾模型时间效率,具备应用前景。
此外,本文尚存以下问题需要后续完善:其一,本文是将原始地震信号经过预处理后提取信号的高维特征进行试验,预处理以及特征提取过程较为复杂,需要具备一定的专业性;其二,本文挑选的
1500 维特征仅仅是在试验中表现比较优异的维度,针对于不同的数据,最佳维度还需要通过试验进一步确定;其三,功率谱、能量谱与倒谱作为高维特征的分类有效性虽然通过试验得到了验证,但针对于不同的数据,最佳特征可能并不一致,因此还需要结合具体数据通过试验来选取最佳特征;最后,本文利用遗传算法对超参数进行了优化选取,当前依旧有新的优化算法不断诞生,因此可以结合新的优化算法探索超参数选取。 -
![]()
图 1 预处理前(左)、后(右)天然地震(a)和爆破(b)的波形对比图
Figure 1. Comparison of waveforms of a natural earthquake (a) and a nuclear explosion (b)before preprocessing (left) with those after preprocessing (right)
-
柏晗,杨耘,崔琴芳,贾鹏,王丽霞. 2022. 基于GA-XGBoost模型的GF-5卫星影像土壤重金属含量反演研究[J]. 激光与光电子学进展,59(12):1230001. Bai H,Yang Y,Cui Q F,Jia P,Wang L X. 2022. Retrieval of heavy metal content in soil using GF-5 satellite images based on GA-XGBoost model[J]. Laser and Optoelectronics Progress,59(12):1230001 (in Chinese). doi: 10.3788/LOP202259.1230001
陈法法,陈保家,程珩,杨晶晶. 2016. 运用免疫遗传算法优化WNN诊断滚动轴承早期故障[J]. 噪声与振动控制,36(6):158–163. Chen F F,Chen B J,Cheng H,Yang J J. 2016. Early fault diagnosis of roller bearings based on wavelet neural network optimized by immune genetic algorithm[J]. Noise and Vibration Control,36(6):158–163 (in Chinese).
陈润航,黄汉明,柴慧敏. 2018. 地震和爆破事件源波形信号的卷积神经网络分类研究[J]. 地球物理学进展,33(4):1331–1338. doi: 10.6038/pg2018BB0326 Chen R H,Huang H M,Chai H M. 2018. Study on the discrimination of seismic waveform signals between earthquake and explosion events by convolutional neural network[J]. Progress in Geophysics,33(4):1331–1338 (in Chinese).
戴邵武,陈强强,戴洪德,聂子健. 2019. 基于平滑先验分析和模糊熵的滚动轴承故障诊断[J]. 航空动力学报,34(10):2218–2226. Dai S W,Chen Q Q,Dai H D,Nie Z J. 2019. Rolling bearing fault diagnosis based on smoothness priors approach and fuzzy entropy[J]. Journal of Aerospace Power,34(10):2218–2226 (in Chinese).
董祎玮,赵建明,李金,刘楚,任佳,王妍,符泽宇,荣伟健,孟令焕. 2017. 曹妃甸地震台网天然地震与爆破波形记录特征[J]. 地震地磁观测与研究,38(3):30–34. doi: 10.3969/j.issn.1003-3246.2017.03.006 Dong Y W,Zhao J M,Li J,Liu C,Ren J,Wang Y,Fu Z Y,Rong W J,Meng L H. 2017. About waveform recording characteristics of natural earthquakes and blasting in Caofeidian seismic network[J]. Seismological and Geomagnetic Observation and Research,38(3):30–34 (in Chinese).
和雪松,李世愚,沈萍,冯全雄. 2006. 用小波包识别地震和矿震[J]. 中国地震,22(4):425–434. doi: 10.3969/j.issn.1001-4683.2006.04.010 He X S,Li S Y,Shen P,Feng Q X. 2006. A wavelet packet approach to wave classification of earthquakes and mining shocks[J]. Earthquake Research in China,22(4):425–434 (in Chinese).
黄汉明,边银菊,卢世军,蒋正锋,李锐. 2010. 天然地震与人工爆破的波形小波特征研究[J]. 地震学报,32(3):270–276. doi: 10.3969/j.issn.0253-3782.2010.03.002 Huang H M,Bian Y J,Lu S J,Jiang Z F,Li R. 2010. A wavelet feature research on seismic waveforms of earthquakes and explosions[J]. Acta Seismologica Sinica,32(3):270–276 (in Chinese).
李欣,俞卫琴. 2020. 基于改进GS-XGBoost的个人信用评估[J]. 计算机系统应用,29(11):145–150. Li X,Yu W Q. 2020. Personal credit evaluation based on improved GS-XGBoost[J]. Computer Systems &Applications,29(11):145–150 (in Chinese).
孟娟,张家声,李亚南. 2022. 基于改进EWT和LogitBoost集成分类器的地震事件分类识别算法[J]. 地震工程学报,44(5):1233–1242. Meng J,Zhang J S,Li Y N. 2022. Classification and recognition algorithm for earthquake events based on the improved EWT and LogitBoost ensemble classifier[J]. China Earthquake Engineering Journal,44(5):1233–1242 (in Chinese).
田宵,汪明军,张雄,王向腾,盛书中,吕坚. 2022. 基于多输入卷积神经网络的天然地震和爆破事件识别[J]. 地球物理学报,65(5):1802–1812. doi: 10.6038/cjg2022P0352 Tian X,Wang M J,Zhang X,Wang X T,Sheng S Z,Lü J. 2022. Discrimination of earthquake and quarry blast based on multi-input convolutional neural network[J]. Chinese Journal of Geophysics,65(5):1802–1812 (in Chinese).
王义国,林峰,李琦,刘钰淇,胡贵洋,孟祥宇. 2024. 基于TCN-LSTM模型的电网电能质量扰动分类研究[J]. 电力系统保护与控制,52(17):161–167. Wang Y G,Lin F,Li Q,Liu Y Q,Hu G Y,Meng X Y. 2024. Classification of power quality disturbances in a power grid based on the TCN-LSTM model[J]. Power System Protection and Control,52(17):161–167 (in Chinese).
隗永刚,杨千里,王婷婷,蒋长胜,边银菊. 2019. 基于深度学习残差网络模型的地震和爆破识别[J]. 地震学报,41(5):646–657. doi: 10.11939/jass.20190030 Wei Y G,Yang Q L,Wang T T,Jiang C S,Bian Y J. 2019. Earthquake and explosion identification based on deep learning residual network model[J]. Acta Seismologica Sinica,41(5):646–657 (in Chinese).
杨帅,郭茂祖,赵玲玲,李阳. 2022. 融合遗传算法与XGBoost的玉米百粒重相关基因挖掘[J]. 智能系统学报,17(1):170–180. Yang S,Guo M Z,Zhao L L,Li Y. 2022. The method of 100-kernel weight related genes mining in maize mixed with genetic algorithm and XGboost[J]. CAAI Transactions on Intelligent Systems,17(1):170–180 (in Chinese).
赵昕迪. 2022. 基于EFA-GA-XGBoost组合预测模型的绝缘子表面污秽程度预测方法[J]. 电子测试,(5):68–70. doi: 10.3969/j.issn.1000-8519.2022.05.018 Zhao X D. 2022. Prediction method of insulator surface pollution degree based on EFA-GA-XGBoost combined prediction model[J]. Electronic Test,(5):68–70 (in Chinese).
Astiz L,Eakins J A,Martynov V G,Cox T A,Tytell J,Reyes J C,Newman R L,Karasu G H,Mulder T,White M,Davis G A,Busby R W,Hafner K,Meyer J C,Vernon F L. 2014. The array network facility seismic bulletin:Products and an unbiased view of United States seismicity[J]. Seismol Res Lett,85(3):576–593. doi: 10.1785/0220130141
Chen T,Guestrin C. 2016. XGBoost:A scalable tree boosting system[C]//KDD ′ 16:Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York:Association for Computing Machinery:785−794.
Choi W,Yang W,Na J,Lee G,Nam W. 2021. Feature optimization for gait phase estimation with a genetic algorithm and Bayesian optimization[J]. Appl Sci,11(19):8940. doi: 10.3390/app11198940
Ewees A A,Al-Qaness M A A,Abualigah L,Oliva D,Algamal Z Y,Anter A M,Ibrahim R A,Ghoniem R M,Elaziz M A. 2021. Boosting arithmetic optimization algorithm with genetic algorithm operators for feature selection:Case study on Cox proportional hazards model[J]. Mathematics,9(18):2321. doi: 10.3390/math9182321
Gomes D E,Iglésias M I D,Proença A P,Lima T M,Gaspar P D. 2021. Applying a genetic algorithm to a m-TSP:Case study of a decision support system for optimizing a beverage logistics vehicles routing problem[J]. Electronics,10(18):2298. doi: 10.3390/electronics10182298
Kekovalı K,Kalafat D,Deniz P. 2012. Spectral discrimination between mining blasts and natural earthquakes:Application to the vicinity of Tunçbilek mining area,Western Turkey[J]. Int J Phys Sci,7(35):5339–5352.
Kiszely M. 2001. Discrimination of quarry-blasts from earthquakes using spectral analysis and coda waves in Hungary[J]. Acta Geodaet Geophys Hung,36(4):439–448. doi: 10.1556/AGeod.36.2001.4.5
Koper K D,Pechmann J C,Burlacu R,Pankow K L,Stein J,Hale J M,Roberson P,Mccarter M K. 2016. Magnitude-based discrimination of man-made seismic events from naturally occurring earthquakes in Utah,USA[J]. Geophys Res Lett,43(20):10638–10645.
Li H R,Li X H,Tan X F,Liu T Y,Zhang Y,Liu J H,Niu C. 2024. Classification of small sample nuclear explosion seismic events based on MSSA-XGBoost[J]. Appl Geophys,21(1):108–118.
Linville L,Pankow K,Draelos T. 2019. Deep learning models augment analyst decisions for event discrimination[J]. Geophys Res Lett,46:3643–3651.
Luat N V,Han S W,Lee K. 2021. Genetic algorithm hybridized with eXtreme gradient boosting to predict axial compressive capacity of CCFST columns[J]. Compos Struct,278:114733. doi: 10.1016/j.compstruct.2021.114733
Ouyang A J,Lu Y S,Liu Y M,Wu M,Peng X Y. 2021. An improved adaptive genetic algorithm based on DV-Hop for locating nodes in wireless sensor networks[J]. Neurocomputing,458:500–510. doi: 10.1016/j.neucom.2020.04.156
Rabin N,Bregman Y,Lindenbaum O,Ben-Horin Y,Averbuch A. 2016. Earthquake-explosion discrimination using diffusion maps[J]. Geophys J Int,207(3):1484–1492. doi: 10.1093/gji/ggw348
Roui M B,Zomorodi M,Sarvelayati M,Abdar M,Noori H,Pławiak P,Tadeusiewicz R,Zhou X J,Khosravi A,Nahavandi S,Acharya U R. 2021. A novel approach based on genetic algorithm to speed up the discovery of classification rules on GPUs[J]. Knowl-Based Syst,231:107419. doi: 10.1016/j.knosys.2021.107419
Stevenson P R. 1976. Microearthquakes at Flathead Lake,Montana:A study using automatic earthquake processing[J]. Bull Seismol Soc Am,66(1):61–80. doi: 10.1785/BSSA0660010061
Stump B W,Hedlin M A H,Pearson D C,Hsu V. 2002. Characterization of mining explosions at regional distances:Implications with the international monitoring system[J]. Rev Geophys,40(4):1011.
Torres M E,Colominas M A,Schlotthauer G,Flandrin P. 2011. A complete ensemble empirical mode decomposition with adaptive noise[C]//2011 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). Prague,Czech Republic:IEEE:4144−4147.
Yavuz E,Sertçelik F,Livaoğlu H,Woith H,Lühr B G. 2019. Discrimination of quarry blasts from tectonic events in the Armutlu Peninsula,Turkey[J]. J Seismol,23(1):59–76. doi: 10.1007/s10950-018-9793-2
Yeh J R,Shieh J S,Huang N E. 2010. Complementary ensemble empirical mode decomposition:A novel noise enhanced data analysis method[J]. Adv Adapt Data Anal,2(2):135–156. doi: 10.1142/S1793536910000422
 下载:
下载:

计量
- 文章访问数: 89
- HTML全文浏览量: 29
- PDF下载量: 19
